Overview
Vowen uses AI in two ways:- AI Enhancement: polishes your transcriptions (grammar, formatting)
- Command Mode: processes voice instructions with full AI capabilities
Supported Providers
Vowen supports 11 providers. Click any provider name in the table to go directly to the page where you generate an API key.
| Provider | Free Tier | Best For | Recommended Model |
|---|---|---|---|
| OpenAI | No (paid) | Best overall quality | GPT-5.4 Nano |
| Anthropic | No (paid) | Nuanced writing | Claude Haiku 4.5 |
| Groq | Yes (generous) | Fast responses, free usage | Llama 3.3 70B Versatile |
| Yes (generous) | Image/video context, free usage | Gemini 2.5 Flash Lite | |
| DeepSeek | Yes (limited) | Budget-friendly | DeepSeek Chat |
| OpenRouter | Varies | Access to 700+ models | Gemini 2.0 Flash (free) |
| Straico | Varies | Multi-model access | Amazon Nova Micro |
| Azure | No (paid) | Enterprise compliance | GPT-4.1 Nano |
| Cerebras | Yes (limited) | Ultra-fast inference | Llama 3.1 8B |
| AWS Bedrock | No (paid) | Enterprise, regional | Amazon Nova Lite |
| Custom API (Pro) | Varies | Self-hosted or OpenAI-compatible endpoints | Your choice |
The free plan supports one configured provider at a time. Custom API and adding multiple providers as backups both require Pro.
Setup Steps
Click Setup on a provider
Each provider card has a Setup button. Click it to open the configuration popup.
Paste your API key
Enter the key from the provider’s dashboard. The popup also has a “See how to retrieve API key here” link that opens the provider’s API key page in your browser.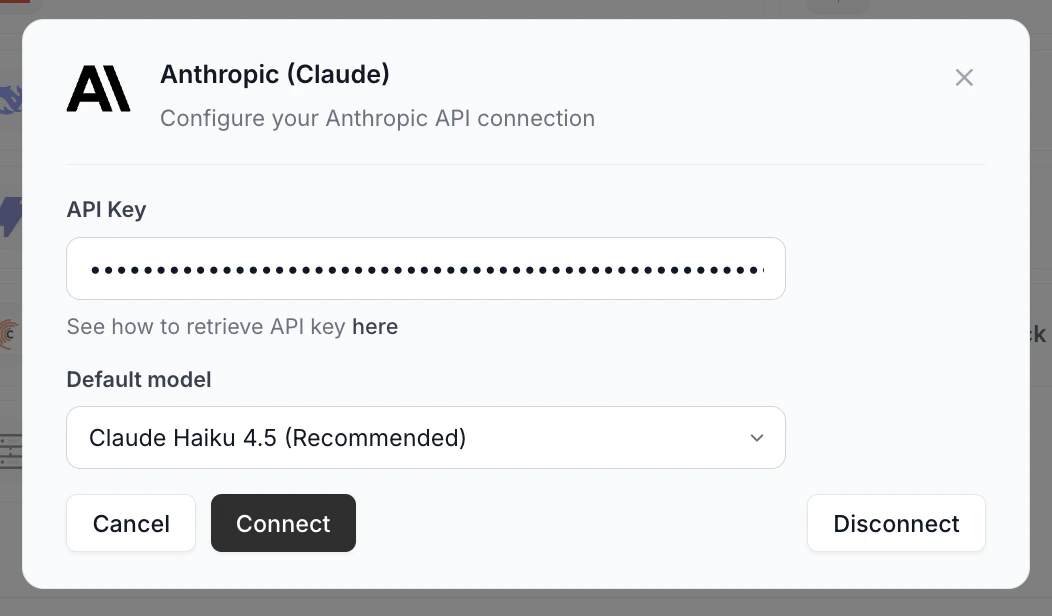
Pick a default model
Choose from the dropdown. The recommended model is pre-selected. Different models offer different speed, quality, and cost trade-offs.
Custom API setup
The Custom API provider works with any OpenAI-compatible endpoint (Ollama, LM Studio, vLLM, self-hosted models, internal gateways). Its setup popup has one extra field.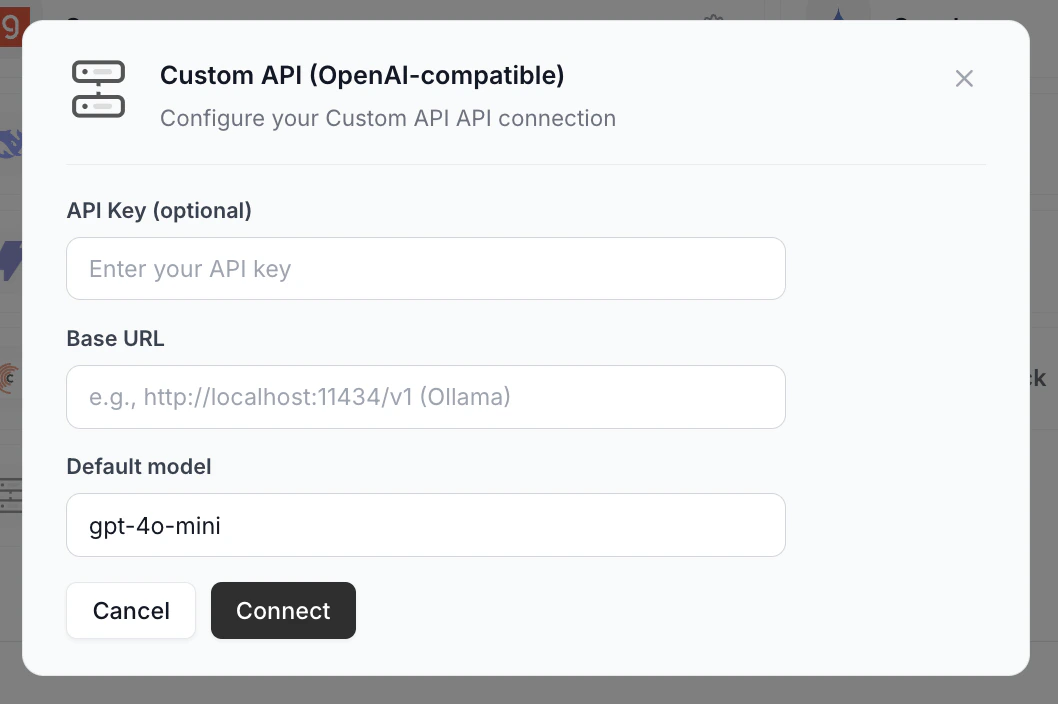
- API Key (optional): leave blank if your endpoint doesn’t require auth.
- Base URL (required): point at your endpoint, e.g.,
http://localhost:11434/v1for Ollama. - Default model: the model identifier your endpoint expects (e.g.,
gpt-4o-mini,llama3.1).
Disconnecting a provider
Open the Setup popup on a connected provider (its card has a gear icon and a green check). A Disconnect button appears in the bottom right. Click it to remove the key and clear the active connection.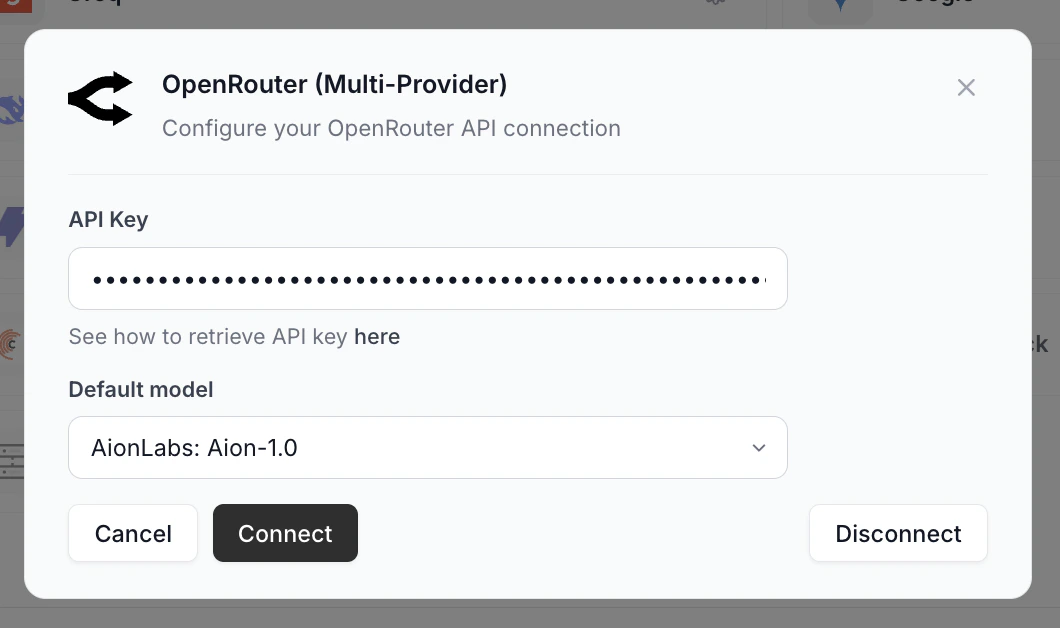
Where to Get API Keys
Each card opens the provider’s developer console where you sign up and generate a key.Free tier
Groq
Generous free tier. Ideal for daily dictation.
Generous free tier with multimodal support.
Cerebras
Free tier with ultra-fast inference.
DeepSeek
Free tier with limited monthly tokens.
Paid
OpenAI
Requires payment method. Top overall quality.
Anthropic
Requires funded credits. Starter credits on signup.
Azure
Requires Azure subscription. Enterprise compliance.
AWS Bedrock
Requires AWS account. Enable models, create key.
Multi-provider gateways
OpenRouter
One key, 700+ models. Several free options.
Straico
One key, multiple providers. Prepaid credits.
Self-hosted
Custom API
Point Vowen at any OpenAI-compatible endpoint. Works with Ollama, LM Studio, vLLM, and self-hosted models.
Switching Providers
Configuring more than one provider is recommended. AI APIs occasionally go down or hit rate limits, and having a second provider connected means you can switch in seconds instead of scrambling to set up a new key mid-outage.- The active provider shows a green check on its card
- Click any configured provider to make it active
- API keys stay saved, so no need to re-enter them when switching
- If your active provider has an outage, switching to a configured backup is one click away
Model Selection
After connecting a provider, click the gear icon on the provider card to select which model to use. Models vary in:- Speed: how quickly responses come back
- Quality: how well it follows instructions and formats text
- Cost: per-token pricing (relevant for paid providers)
Rate Limits
If you hit rate limits (especially on free tiers):- Switch between providers (e.g., alternate between Groq and Gemini)
- Use a larger model that has higher limits
- Wait a few minutes for limits to reset
- Consider upgrading to a paid tier for heavy usage
Security
Your API keys are:- Encrypted at rest using your OS’s secure keystore (Keychain or DPAPI)
- Never sent to Vowen servers, only to your selected AI provider
- Stored locally on your machine, never on our infrastructure